
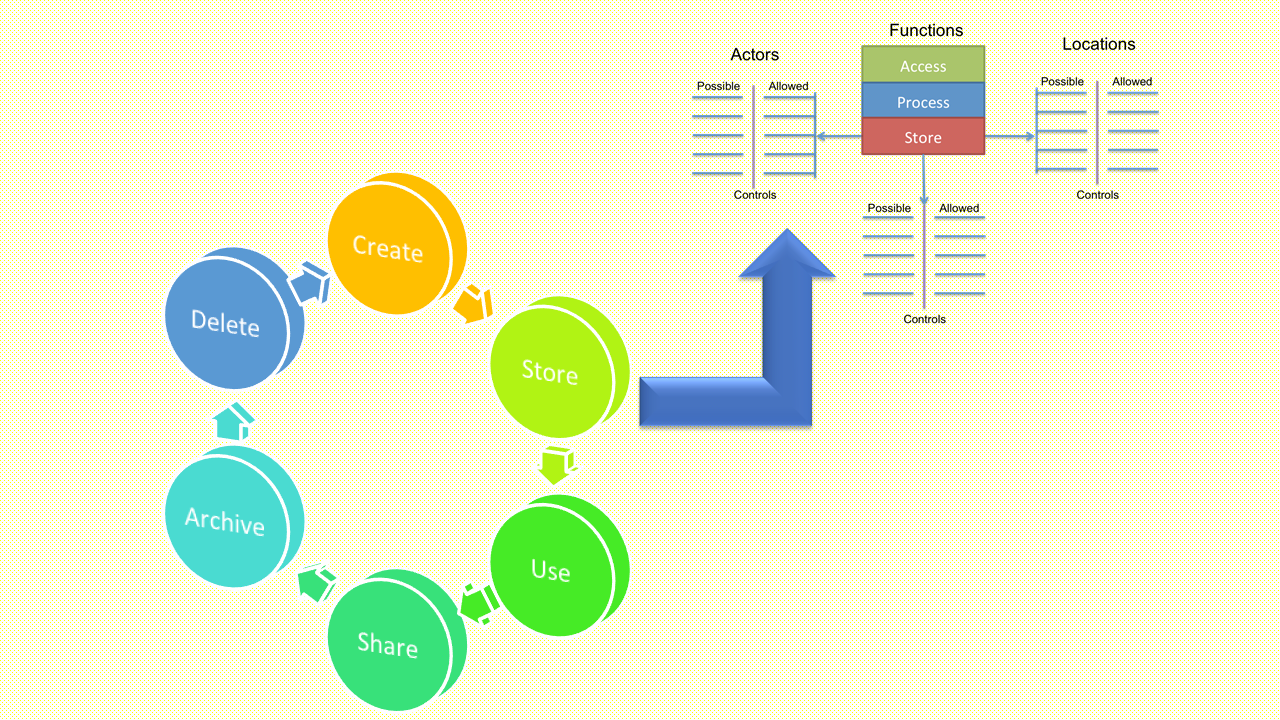
The Cloud Security Alliance Guidance explains the Data Security Lifecycle which mentions the various phases data undergoes in the cloud. This lifecycle was adapted from a blog article on Securosis. Rich Mogull, Analyst & CEO, stated that he was not happy with his work since it seemed rushed and did not sufficiently address the cloud aspects. They have released the Data Security Lifecycle 2.0 and this blog post attempts to present it in simple terms.
Before we delve into the nuances of the improved version of the life cycle, a sneak peek into the old one would help us appreciate the changes. The V1.0 is depicted below.
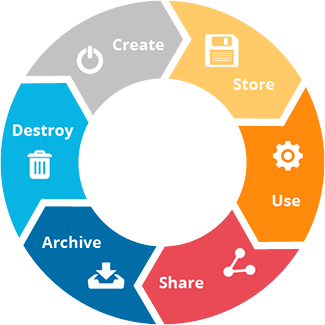
The lifecycle has a total of six phases - Create, Store, Use, Share, Archive, and Destroy. While the depiction in a circular step-by-step manner may seem that one phase follows the other, it is not so. Creating and storing may happen simultaneously and archive may not happen if the information is not required to be stored for long-term purposes. In essence, the data may or may not flow through all these phases, but all such phases exist and are valid for the data created by the data owners.
The phases are as follows :
- Create: This is probably better named Create/Update because it applies to creating or changing a data/content element, not just a document or database. Creation is the generation of new digital content or the alteration/updating of existing content.
- Store: Storing is the act of committing the digital data to some sort of storage repository and typically occurs nearly simultaneously with creation.
- Use: Data is viewed, processed, or otherwise used in some sort of activity.
- Share: Data is exchanged between users, customers, and partners.
- Archive: Data leaves active use and enters long-term storage.
- Destroy: Data is permanently destroyed using physical or digital means (e.g., crypto shredding).
So what made Rich and other authors feel that this life cycle does not capture all the aspects of data in the case of cloud computing?
The two parameters which they propose to add to the lifecycle are - Locations & Access.
Compared to traditional computing, which limited access to data (accessing/ sharing/ storing) from certain places ( only offices), cloud computing brings flexibility to these parameters. Traditional computing had evolved to offer flexibility, but it still lacks a lot of conveniences and anytime and any location access as compared to cloud computing.
Let’s delve into these parameters in detail as explained by Rich.
Locations
The traditional form of computing involved an organization setting up a data center and all the employees had to access any information from this data center via the office premises (a secured form of networking as they call it).
Cloud computing questions all of this by bringing in a variety of cloud deployment models - public, private, hybrid, community, and the three service models - IAAS, PAAS, and SAAS. Deployment of such models ensures that data transitions between a variety of storage locations, applications, and operating environments. Even data created in a locked-down application may find itself backed up someplace else, replicated to alternative standby environments, or exported for processing by other applications. And all of this can happen at any phase of the Lifecycle. Furthermore, these locations may be internal, external, company-owned, etc.
Hence the life cycle must have a component related to location.
Access
The next flavor which Rich brings to this complex dish is when he adds the access component. When there is data, it will be accessed ( shared, modified). Now when the data moves via various phases, it’s important that we must question the following :
- Who accesses the data?
- How can they access it (device & channel)?
The cloud allows us to access data from any device - laptops, mobile phones, tablets - personal as well as company-owned. The device and channel bring a lot of complexity from a security perspective. Some applications behave differently over a mobile or tablet as compared to laptop or desktop implementations. Add a pinch of further complexity, if you have subcontractors and their organization’s devices to deal with.
The WHO accesses the data - The life cycle misses this important part. The actors who will create, share, modify, archive, or destroy the information.
If we look at what we have achieved till now, the summary would be as follows:
Data Security Life Cycle 1.0 + Location + Access ( Actors /Devices)
Do you feel that this equation makes it to equal to V2.0? Not yet.
So the question that comes to your mind is - what is/are the missing ingredients?
This is something that we security professionals add the moment we evaluate a business solution from a security perspective.
Controls
Controls ensure that the authorized person performs the authorized function. If you have access to just read the data from a blog ( just like you are reading now), I will be putting in controls to ensure that you would not be able to modify or delete the blog post.
Imagine an access control list/ entitlement list, where you list down the options, the basis on which a system decides whether you can access the document or not.
The final consideration is the data itself.
Functions
Rich mentions that there are three things we can do with a given datum:
- Access: View/access the data, including copying, file transfers, and other exchanges of information.
- Process: Perform a transaction on the data: update it, use it in a business processing transaction, etc.
- Store: Store the data (in a file, database, etc.).
Individually looking at these aspects and it is starting to sound a bit confusing. I agree, but we need to look at the holistic picture to appreciate what Rich is trying to tell us.
I will summarise in Rich’s words:
“In essence, what we’ve produced is a high-level version of a data flow diagram (albeit not using standard programming taxonomy). We start by mapping the possible data flows, including devices and different physical and virtual locations, and at which phases in its lifecycle data can move between those locations. Then, for each phase of the lifecycle in a location, we determine which functions, people/systems, and more granular locations for working with the data are possible. We then figure out which we want to restrict, and what controls we need to enforce those restrictions.”
Bringing in elements that actually control the security of the data lifecycle is an important first step. Add in the practical challenges and current work-from-anywhere practices in the pandemic, this is a cocktail of complexity. To navigate through these challenges, it is imperative that companies employ experts in this field.
The original article can be accessed here.

Comments ()